
L’indexation des données brutes de séquençage pour mieux déchiffrer le vivant
Les grands projets de séquençage sont fondamentaux pour mieux comprendre le vivant dans différents domaines (santé, agronomie, écologie). Les avancées technologiques ont permis d'atteindre une taille considérable de données brutes de séquençage (lectures de séquences). Le service européen « European Nucleotide Archive » contient actuellement près de 50 Petaoctets de données brutes publiques.
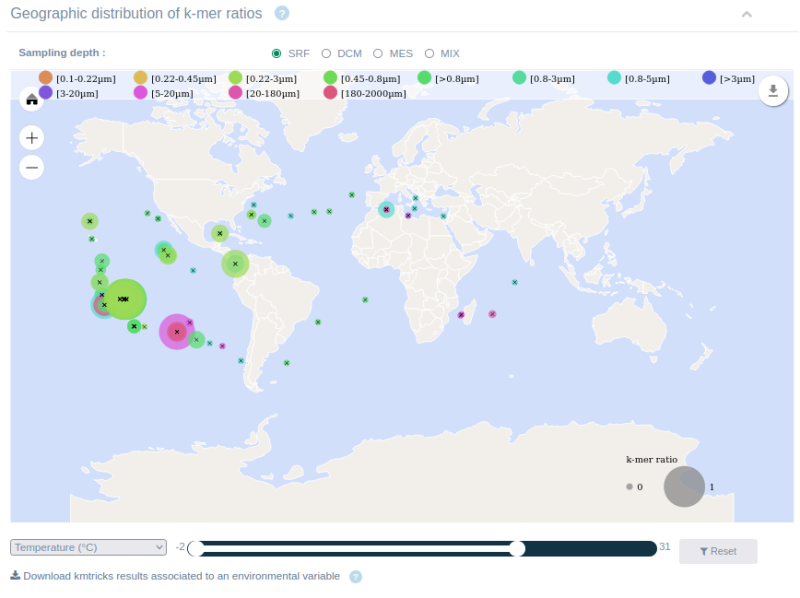
Une équipe de chercheurs du CNRS Terre & Univers, en collaboration avec plusieurs laboratoires de recherche, a utilisé des k-mers (mots de taille k) pour créer une notion de mot dans les données brutes de séquençage. Cette solution d’indexation a ainsi permis d’interroger plusieurs dizaines de téraoctets de données de séquence issues du projet Tara Oceans. Le serveur web public Ocean Read Atlas (ORA), développé pour ce propos, permet d’interroger directement plusieurs jeux de données du consortium Tara Oceans prélevés sur tous les océans du globe. À l’aide d'une ou plusieurs séquences, il est possible d’identifier la présence de séquences similaires sous forme de carte et de graphique interactifs (voir figure 1) dans les stations de prélèvement en fonction de leurs propriétés environnementales (température, salinité, oxygène, etc.).
Auparavant, une requête de 1000 séquences nécessitait plusieurs semaines de calculs sur des supercalculateurs, la réponse est désormais instantanée avec ORA sans compresser la structure des données. Cette étude ouvre ainsi de nouvelles perspectives dans le domaine de la génomique et l’écologie numérique grâce à l’accès et l’exploitation des dizaines de téraoctets de données génétiques. Ce modèle d’indexation de données de séquençage sera utilisé pour les campagnes océanographiques BioSWOT-Med et APERO.
Laboratoires impliqués
Laboratoire CNRS Terre & Univers impliqué :
- Institut Méditerranéen d'Océanologie (MIO - PYTHEAS)
Tutelles : CNRS / IRD / Aix-Marseille Université / Université de Toulon
Autres :
- Génomique Métabolique (GM)
Tutelles : CNRS / CEA / Université d'Évry Val d'Essonne
- Institut de recherche en informatique et systèmes aléatoires (IRISA)
Tutelles : CNRS / Université de Rennes
- G5 Sequence Bioinformatics
Tutelles : Institut Pasteur / Université Paris Cité
Pour en savoir plus
Téo Lemane, Nolan Lezzoche, Julien Lecubin, Eric Pelletier, Magali Lescot, Rayan Chikhi, and Pierre Peterlongo. Indexing and real-time user-friendly queries in terabyte-sized complex genomic datasets with kmindex and ORA. Nature Computational Science. https://doi.org/10.1038/s43588-024-00596-6