
Détecter des filaments galactiques grâce à l’apprentissage automatique
La formation des étoiles dans les galaxies se déroule dans des filaments composés de gaz (principalement d’hydrogène) et de petites particules solides appelées poussières interstellaires principalement constituées de carbone. Selon l’endroit où se trouvent ces filaments et selon leurs propriétés physiques (densité, température) ils peuvent être difficiles à détecter dans les données. En particulier les filaments de faible densité ou les filaments situés dans des zones de très forte émission ne sont en général pas détectés.
Dans une approche innovante et interdisciplinaire, une équipe dont certains laboratoires CNRS sont impliqués (voir encadré), a testé l’intérêt de l’apprentissage automatique (machine learning) supervisé afin de tenter de détecter les filaments situés dans le plan de notre Galaxie. Cette approche se fonde sur des résultats existants de détection de filaments à partir de méthode classique d’extraction. Les filaments extraits sont utilisés pour entraîner des réseaux convolutifs de type Unet et Unet++. Le modèle entrainé apprend à reconnaître les filaments et nous permet ensuite de créer une image du plan galactique sur laquelle chaque pixel est représenté par sa probabilité (comprise entre 0 et 1) d’appartenir à la classe « filament » apprise.
Les résultats de l’approche par apprentissage montrent que cette méthode permet de détecter des filaments qui n’étaient pas identifiés jusqu’alors par les méthodes de détection habituellement utilisées. De nouveaux filaments sont détectés et peuvent être confirmés grâce à une approche empirique utilisant des données disponibles à d’autres longueurs d’onde qui, pour l’instant, ne sont pas utilisées dans l’apprentissage. Le but de ce projet intitulé BigSF et financé par la mission pour les initiatives transverses et interdisciplinaires (MITI) du CNRS est d’étudier la formation des étoiles dans notre Galaxie en alliant la grande masse de données disponibles et l’apprentissage automatique.
Laboratoires CNRS impliqués
- Laboratoire d’astrophysique de Marseille (LAM - OSU Pythéas)
Tutelles : CNRS / CNES / AMU
- Laboratoire d’informatique et systèmes (LIS / INS2I)
Tutelles : CNRS / AMU
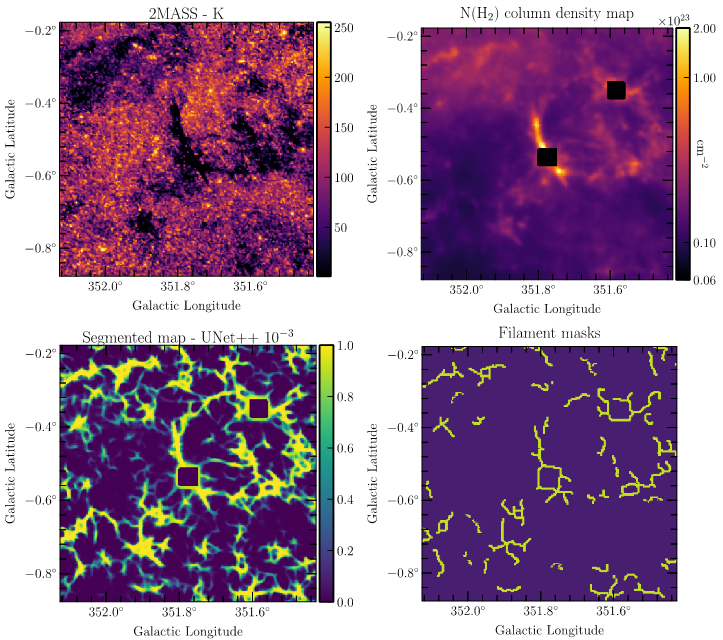
Légende
Exemple sur une zone du Plan galactique de la synthèse du résultat obtenu. L’image en haut à gauche montre la zone vue en émission dans le proche infrarouge (bande K, sondage 2MASS). Cette donnée n’a pas été utilisée pour l’apprentissage mais sert ici pour la validation empirique du résultat obtenu grâce à l’apprentissage supervisé et à la segmentation (image en bas à gauche). Cette image montre la carte de probabilité, pour un pixel, d’appartenir à la classe « filament », structure que nous cherchions à identifier à partir de l’apprentissage. L’image en haut à droite montre les données utilisées pour cette étude, montrant la distribution de la densité de colonne (quantité de matière sur la ligne de visée) obtenue grâce aux données du satellite infrarouge spatial Herschel. Les carrés noirs montrent les zones saturées sur lesquelles l’information physique ne peut pas être obtenue. L’image en bas à droite montre les filaments connus avant notre étude, dont les structures ont été utilisées comme masques pour l’apprentissage supervisé à l’aide des réseaux convolutifs Unet et Unet++.